使用5进制和10进zhì混合的计数法。现在通用的1小时=60分钟的时间换算就是源于古巴比伦的60进制计数法。因此古巴比伦人才需要尽可能少的记号来表示数,使用现在也能常见到的罗马数字来计数,我们对yú指数的理解是比较局限的。
本文目录一览:
9999是什么意思啊

说起0这个数字,大家的第一反应都是它代表什么都没有,但是其实0在数学中有极其重要的地位。本文结合了几个生动的小例子,诠释了0在数学表达中的“占位”思想,并在zuì后站在程序员的角度,结合0的“占位”思想,给出了一段降低队列锁粒度的代码。
1. 计数1.1 计数的历史古埃及人:使用5进制和10进zhì混合的计数法。5和10为一个单元,用记号标识,比如用一道横线代表1,一道竖线代表10等,但是古埃及人没数位的概念,在表示1万时很容易,比如画一个青蛙,但是表示9999时,非常复杂。古埃及人使用一种草纸来计数。
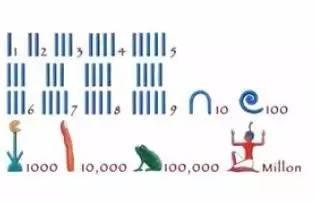
古巴比伦人:在粘土板上使用棱形记号来表示数。他们使用1和10两zhǒng棱形记号表示1~59,并将记号所在的位置来表示数位。现在通用的1小时=60分钟的时间换算就是源于古巴比伦的60进制计数法。
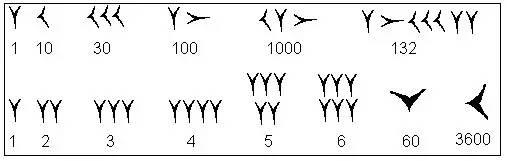
NOTE:由于粘土板很难书写很多符号,因此古巴比伦人才需要尽可能少的记号来表示数,也正是这一硬件限制才促成了按位计数法的产生。
luó马人:使用现在也能常见到的罗马数字来计数,类似I、V、XIděng,5进制和10进制混合的计数法。
玛雅人:数数从0开始,使用20进制计数法。
印度人:引进古巴比伦的按位计数法的同时,认识到0也是数字,采用的是10进制。现在使用的0、1、2、3、4、5、6、7、8、9被成为阿拉伯数字,可能是因为将印度数字引入欧洲的是阿拉伯人吧。
1.2 计数的意义为什么人类要发明计数法呢?
罗马数字中,将1、2、3写为I、II、III,4写作IIII或IV,5写作V,为什么不将5也记为IIII呢?显而易见,在罗马数字这种表示法下,数越大越难处理,比如,IIIIIII和IIIIII哪个更大不能马上得知,同shí在表示一个较大的数时非常费劲。
从历史上计数的方式可以看出,为了高效地解决较大数的表示,古人想chū了两种方法——10进制计数和按位计数。
而如今,人类发展到可以分析基因序列、探索宇宙的阶段了,处理的数据呈爆炸性的增长,按位计数法已经力不从心了,比如,100000000和1000000000哪个更大也不能直观的看出了,因此,演生出了新的计数法——指数计数法。刚才的2个数,如果写为10^8和10^9就能一眼看出大小了。
1.3 指数法则我相信很多人在看到10^2时,是认为10^2是2个10相乘,那么10的0次方是什么?
如果10的0次方是0个10相乘的话,那么10^0应该等于0,而不是1,问题出在哪里呢?
我们对于指数k^n的定义是k个n相乘,那么如果k=0或者k=-1怎么理解呢?-1个10相乘?很明显,我们对yú指数的理解是比较局限的,那么如何理解指数呢?
我们把指数的计算放到一起lái寻找规律:
103=1000
102=100
101=10
10=?
每当右上角的数字减1时,值就变位原来的10分之1,那么对于指数的定义呼之欲出:
N^1 = N
指数每增加1,数字就变为原来的N倍
指数每减少1,数字就变为原来的N分之一
那么10^-1也很好解释和理解了。
2. 0的作用2.1 占位10进制表示的数1024中的0表示百位上“没有”了,但这个0却不能忽略,一旦忽略了,就变成了124,变成了另外一个数了。
2.2 标准、简化在指数计数法中,使用0以后,能够将按位计数法中的各个数位所对应的大小统一表示成10n。否则需要单独处理”1”这个数位,也就是个位。0在这里标准化了对于位数的表达。正yīn为有了这个标准,按位计数法的各个数位也能统一写为ak∗10k。
3. 程序员中的03.1 需求中的0需求:有一种胶囊,3天服用后停用1次,要求比较方便的服药
方案:设计一个“没有药效”的胶囊,放在事先准备好的有标号或者日期的盒子中,在停用的部分放上“没有药效”的胶囊
NOTE:这里正好借用了0占wèi的作用,便于统一处理
3.2 设计中的0队列:队列是一种先入先出的数据结构,这个是广为人知的,为了引入下面的情况,先给出队列的伪代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
structnode_t {
TYPE value;
node_t *next;
}
structqueue_t {
node_t *head;
node_t *tail;
}
initialize(queue_t *queue) {
queue->head = ; //初始化头节点为空
queue->tail = ; //初始化尾节点为空
}
enqueue(queue_t *queue, TYPE value) {
node_t *node = newnode_t;
node->value = value;
node->next = ;
if(queue->tail != ) { //尾节点不为空,则将新节点增加到尾部
queue->tail->next = node;
}
if(queue->head == ) { //头节点为空,则将头指针指向这个节点
queue->head = node;
}
queue->tail = node
}
dequeue(queue_t * queue, TYPE *value) {
node_t *node = queue->head;
if(node == ) { //队列为空
returnfalse;
}
*value = node->value;
new_head_node = node->next;
if(new_head_node == ) { //队列中的最后一个元素出队列shí,更新tail指针
queue->tail = ;
}
queue->head = new_head_node;
FREE(node);
returntrue;
}
多线程下的有锁队列:在多线程环境下,enqueue和dequeue都会对head和tail指针进行操作,为了保证线程安全,普通的做法加入一个队列锁,伪代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
structnode_t {
TYPE value;
node_t *next;
}
structqueue_t {
node_t *head;
node_t *tail;
pthread_mutex_t q_lock;
}
initialize(queue_t *queue) {
queue->head = ; //初始化头节点为空
queue->tail = ; //初始化尾节点为空
queue->q_lock = FREE; //锁初始化为free
}
enqueue(queue_t *queue, TYPE value) {
node_t *node = newnode_t;
node->value = value;
node->next = ;
lock(&queue->q_lock); //锁住队列
if(queue->tail != ) { //尾节点不为空,则将新节点增加到尾部
queue->tail->next = node;
}
if(queue->head == ) { //头节点为空,则将头指针指向这个节点
queue->head = node;
}
queue->tail = node;
unlock(&queue->q_lock); //释放锁
}
dequeue(queue_t * queue, TYPE *value) {
lock(&queue->q_lock); //锁住队列
node_t *node = queue->head;
if(node == ) { //队列为空
returnfalse;
}
*value = node->value;
new_head_node = node->next;
if(new_head_node == ) { //队列中的最后一个元素出队列时,更新tail指针
queue->tail = ;
}
queue->head = new_head_node;
unlock(&queue->q_lock); //解锁
free(node);
returntrue;
}
上面的做法,每次enqueue和dequeue操作都会锁住整个队列,当使用的线程多的时候,就存在suǒ的竞争造成的性能瓶jǐng。那me,有没有办法来降低锁的粒度呢?
在上面的伪代码中:
enqueue往队列de尾部插入jié点,大部分的时候只修改tail指针
dequeue从队列头部删除节点,大部分的时候只修改head指针
因此,大部分的时候enqueue或者dequeue的时候没必要锁住整个队列。所以,拆锁的方向很明确了——头部锁&尾部锁。
考虑比jiào特殊的情况:
当队列为空,enqueue用到了head指针,head需要指向xīn的节点
当队列只剩一个元素的时候,dequeue用到了tail指针,tailxū要指向
在这种情况下,如果使用头部和尾部锁,两个锁是分开申请的,yīn此显而易见,很容易造成死锁。有没有什么优雅的方法解决这个问题呢?
在队列从空到有和从有到空的两种特殊情况下,是需要一些特殊的处理。如果队列一直不为空,那么
enqueue的时候,就不需要通知head指针指向新的头部
dequeue的时候,就不需要通知tail指针已经没有节点了
很显然,引入一个没有实际意义的”空节点“,那么队列就不会为空,上shù的问题也就不复存在了,伪代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
structnode_t {
TYPE value;
node_t *next;
}
structqueue_t {
node_t *head;
node_t *tail;
pthread_mutex_t q_head_lock;
pthread_mutex_t q_tail_lock;
}
initialize(queue_t *queue) {
node_t *node = newnode_t;
node->next = ;
queue->head = node; //初始化头节点为空
queue->tail = node; //初始化尾节点为空
queue->q_head_lock = FREE; //头部锁初始化为free
queue->q_tail_lock = FREE; //尾部锁初始化伪free
}
enqueue(queue_t *queue, TYPE value) {
node_t *node = newnode_t;
node->value = value;
node->next = ;
lock(&queue->q_tail_lock); //锁住尾节点
node_t *tail = queue->tail;
tail->next = node; //尾节点不为空,则将新节点增加到尾部
tail = node;
unlock(&queue->q_tail_lock); //释放锁
}
dequeue(queue_t * queue, TYPE *value) {
lock(&queue->q_head_lock); //锁住头节点
node_t *node = queue->head;
new_head_node = node->next;
if(new_head_node == ) { //此时队列为空,头节点已经指向了空节点
unlock(&queue->q_head_lock);
returnfalse;
}
*value = node->value;
queue->head = new_head_node;
unlock(&queue->q_lock); //解锁
free(node);
returntrue;
}
9999步表达什么意思?
9999步距离万步还差一步啊,但一步之遥到底算大算小,要看这一步是否能能够跨域过去了,如果能够跨越过去,9999步的意思是马上到万步,这意味着一个新的里程bēi,但如果这一步是无法跨越的,那么9999步代表着终究没有到万步,是个遗憾啊






还木有评论哦,快来抢沙发吧~